Zwizualizowane dane pomagają nam lepiej zrozumieć informacje, które mają być przekazane. Nieprzypadkowo w prezentacjach umieszcza się dane w postaci wykresów słupkowych lub innego typu reprezentacji graficznej. Skorzystanie z odpowiedniej formy graficznej wymaga dobrego przemyślenia. Chcemy, aby nasz przekaz był dobrze zrozumiany przez osobą, do której kierujemy taką formę graficzną. Wbrew pozorom storytelling danych może należeć do czynności trudnych.
Wpis ten podzieliłem na dwie części, do każdego z przykładów umieszczam kod w Pythonie, który możesz wypróbować w narzędziu Google Collab lub Jupyter Notebook.
Mapy cieplne(heat map)
Przedstawiają dane w matrycy przy użyciu kolorów. Zwykle są one zgodne z temperaturą barwową danego koloru, np. czerwony, pomarańczowy, niebieski. Najczęściej pomagają podkreślić i porównać znaczenie kluczowych obszarów.
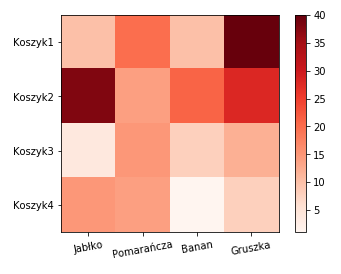
import matplotlib.pyplot as plt
import pandas as pd
df = pd.DataFrame([[10, 20, 10, 40], [38, 14, 21, 28], [4, 15, 8, 12],
[15, 14, 1, 8]],
columns=['Jabłko', 'Pomarańcza', 'Banan', 'Gruszka'],
index=['Koszyk1', 'Koszyk2', 'Koszyk3', 'Koszyk4']
)
plt.imshow(df, cmap="Reds")
plt.colorbar()
plt.xticks(range(len(df)),df.columns, rotation=10)
plt.yticks(range(len(df)),df.index)
plt.show()Wykres słupkowy(bar chart)
Wykres słupkowy grupuje dane w proporcjonalne słupki informacji, które mogą być wyświetlane zarówno w pionie jak i poziomie. Ten typ wykresu jest dobrym rozwiązaniem, jeżeli chcemy porównać dane ilościowe w odniesieniu do x i y.
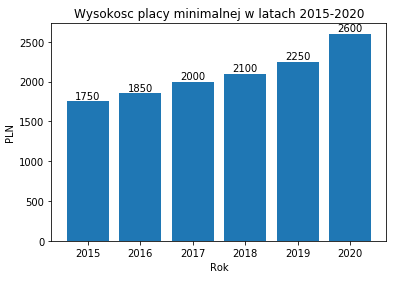
import matplotlib.pyplot as plt
year = [2015, 2016, 2017, 2018, 2019, 2020]
unit = [1750, 1850, 2000, 2100, 2250, 2600]
plot = plt.bar(year, unit)
# Dodanie PLN nad slupkiem
for value in plot:
height = value.get_height()
plt.text(value.get_x() + value.get_width()/2.,
1.002*height,'%d' % int(height), ha='center', va='bottom')
plt.title("Wysokosc placy minimalnej w latach 2015-2020")
plt.xlabel("Rok")
plt.ylabel("PLN")
plt.show()Histogramy i rozkład prawdopodobieństwa
W przypadku tej formy wizualizacji możesz przedstawić dane ilościowe. Są odpowiednie do danych podkreślających szczyty i minima w naszym zbiorze danych.
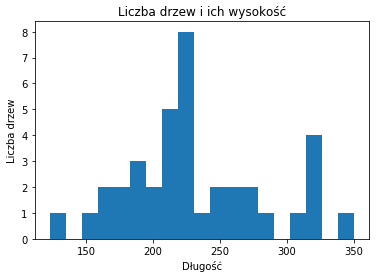
import numpy as np
import matplotlib.pyplot as plt
# Data in numpy array
exp_data = np.array([230, 178, 190, 230, 176, 195, 268, 219, 190, 279, 230, 230, 235, 245, 167, 195, 230, 149, 167,
350, 320, 325, 230, 194, 123, 220, 215, 210, 267, 210, 249, 257, 261, 210, 320, 210, 310, 315])
# Plot the distribution of numpy data
plt.hist(exp_data, bins = 19)
# Add axis labels
plt.xlabel("Długość")
plt.ylabel("Liczba drzew")
plt.title("Liczba drzew i ich wysokość")
plt.show()Wykres liniowy(line chart)
Jeden z najpopularniejszych wykresów. Łączy punkty na wykresie z pomocą linii, najczęściej łamanej, od pierwszej wartości do ostatniej. Wykresy liniowe są przydatne do pokazywania zmian lub trendów.
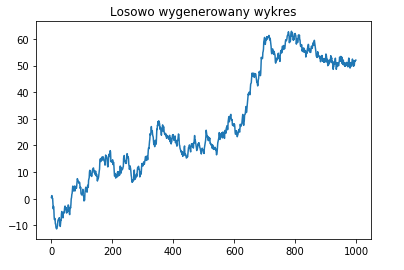
import matplotlib.pyplot as plt
import numpy as np
# Losowe wygenerowanie wartości
values=np.cumsum(np.random.randn(1000,1))
plt.title("Losowo wygenerowany wykres")
plt.plot(values)Część druga niebawem 🙂
- Rozwiązywanie problemów na poziomie Hive Metastore
- Jak zainstalować pakiet .rpm na WSL(Ubuntu)?
- Kerberos i Hadoop – typowe problemy. Jak je rozwiązać?
- Hive – export i import tabel. Jak wykonać?
- Przetwarzanie tekstu z wykorzystaniem narzędzia AWK